速览目录 · Top 10
| # | 论文 | 领域 | Votes |
|---|---|---|---|
| 1 | InCoder-32B | 代码大模型 | 131 |
| 2 | MiroThinker-H1 | 研究 Agent | 130 |
| 3 | Qianfan-OCR | 文档理解 / OCR | 79 |
| 4 | Kinema4D | 具身智能 / 世界模型 | 62 |
| 5 | 视频扩散推理机制(Chain-of-Steps) | 视频生成 / 可解释性 | 55 |
| 6 | WorldCam | 世界模型 / 视频生成 / 3D 一致性 | 43 |
| 7 | TRUST-SQL | NLP / Text-to-SQL / 强化学习 | 43 |
| 8 | LEAD | 多模态 / 幻觉缓解 / 解码策略 | 35 |
| 9 | OEL(在线经验学习) | LLM 持续学习 | 34 |
| 10 | FinToolBench | Agent 评测 / 金融 AI | 29 |
今日主线一:工业级代码智能——InCoder-32B(131↑)从零训练 32B 代码模型覆盖 CUDA 内核、芯片 RTL、嵌入式等五大工业场景,通用模型调用成功率仅 28.8% 的领域它做到了工业可用。主线二:研究 Agent 的验证革命——MiroThinker-H1(130↑)不再让推理链"蒙眼狂奔",而是在每一步内嵌验证机制,局部修正+全局审计让深度研究任务达到 SOTA。主线三:视频扩散模型可解释性突破——推翻"帧间推理"假说,证明推理能力沿去噪步骤涌现。
Insight:当代码模型从"通用编程"走向"工业专用",当推理 Agent 从"生成更多 token"走向"验证每一步 token",AI 工具的成熟度正在从"能用"跃升到"可信赖"。
InCoder-32B:面向工业场景的代码基础大模型

通用代码大模型在 LeetCode、HumanEval 等基准上表现亮眼,但当面对芯片设计、GPU 内核调优、嵌入式固件这类工业编程场景时,性能往往急剧下滑——现有最强模型的工业任务调用成功率仅有 28.80%。这一断层正是 InCoder-32B 的出发点。
来自北航、IQuest Research 等多家机构的团队从零训练了这个 32B 参数的工业代码基础模型,覆盖五大工业领域:芯片设计(Verilog/VHDL)、GPU 内核优化(CUDA)、嵌入式系统(C/汇编)、编译器优化(LLVM IR)以及 3D 建模(CAD/CAM)。
训练流程分为四个阶段:①通用代码预训练打底;②精选工业代码退火,注入领域专有数据;③中间训练阶段渐进式将上下文从 8K 扩展至 128K token,并引入合成工业推理数据;④基于执行结果的验证后训练(execution-grounded post-training),以实际运行反馈纠正模型输出。
论文展示了一个典型案例:对 512×512 大尺寸的 RMS Normalization 做 CUDA 优化时,Claude 将 spatial_size(262,144)直接赋给 gridDim.y,超过 CUDA 硬件上限 65,535 导致运行时错误;而 InCoder-32B 能识别硬件约束,将维度展平为 1D grid 规避问题——这正是理解硬件语义的体现。
评估结果显示:在 14 个主流通用代码基准上保持竞争力的同时,InCoder-32B 在覆盖 4 个专业领域的 9 个工业基准上建立了开源 SOTA 基线。这是目前公开可得的、规模最大且覆盖最广的工业代码基础模型,对芯片 EDA 流程自动化、高性能计算内核生成等方向具有直接应用价值。
MiroThinker-H1:通过推理链验证机制提升 Agent 深度研究可靠性
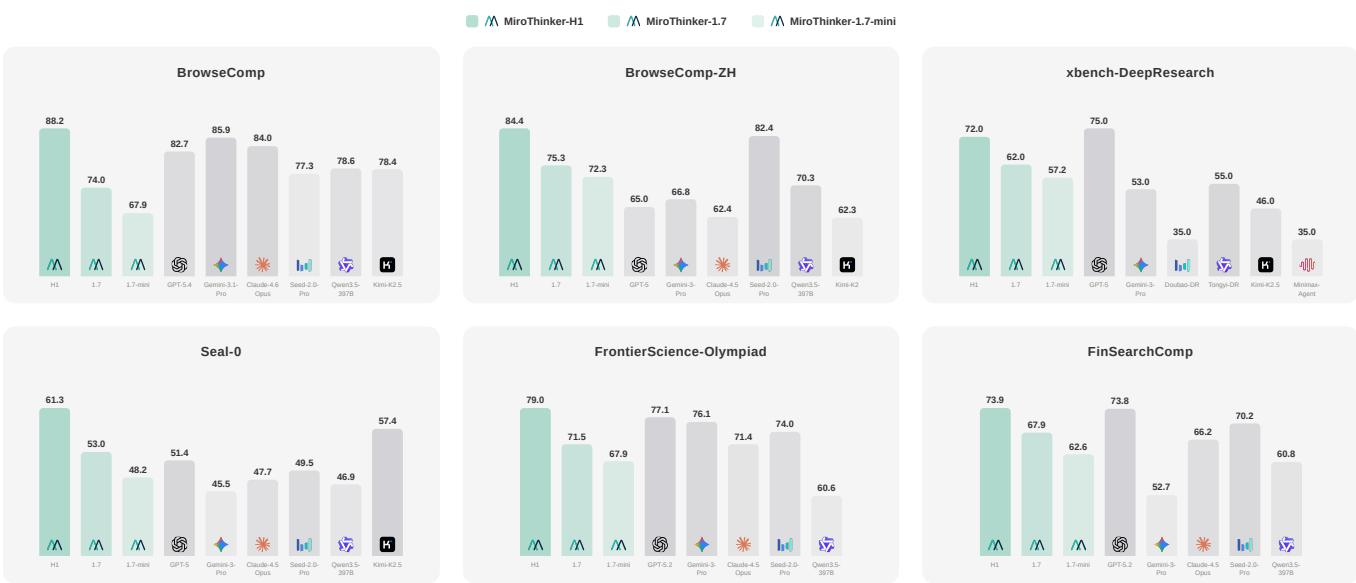
长链推理 Agent 有一个普遍痛点:当中间步骤出现错误或依据不足时,更多的推理轮次反而会累积噪声、放大错误,最终答案质量反而下降。MiroMind 团队认为,解决方案不是盲目加长推理链,而是提升每一步交互的有效性。
论文提出两个递进版本:MiroThinker-1.7 引入「Agentic Mid-Training」阶段,通过大规模结构化监督训练,强化模型在规划、上下文推理和工具调用上的单步原子能力,使每轮交互更可靠、更信息丰富;MiroThinker-H1 则在此基础上,将验证机制嵌入推理过程本身——在局部层面,中间推理决策可在推理时被评估和修正;在全局层面,整条推理轨迹会被审计,确保最终答案有完整的证据链支撑。
训练流程包含完整四阶段闭环:Mid-Training → SFT → 偏好优化 → 强化学习。Mid-Training 阶段特别引入了冷启动规划、上下文条件推理、中间摘要等多样化的 Agentic 监督形式,让模型学会更可靠地分解复杂任务。
在开放网络研究、科学推理、金融分析三类基准上,MiroThinker-H1 在深度研究任务上取得 SOTA,同时在专业领域保持强竞争力。与上一代 MiroThinker-1.5 相比,1.7 版本用更少的推理轮次完成同等复杂任务。团队同步开源了 MiroThinker-1.7 及 MiroThinker-1.7-mini 的权重,供研究者复现和扩展。
这项工作的核心贡献在于将「验证」从事后评估提升为推理过程的内生机制,为构建可审计、可信赖的重型研究 Agent 提供了清晰的技术路径。
Qianfan-OCR:端到端文档智能模型如何在布局理解上反超多阶段流水线
核心问题:传统 OCR 存在两条路线的内在矛盾——多阶段流水线拥有精确的布局分析能力,但级联误差会逐级放大;端到端模型避免了误差传播,却丢失了显式的空间定位能力。百度千帆团队的 Qianfan-OCR 试图在 4B 参数量内同时解决这两个问题。
Layout-as-Thought 机制是本文最关键的创新。当用户在 prompt 中插入 think 标记时,模型会在输出最终 Markdown 前,先生成一段结构化的思考过程——包含每个文档元素的边界框坐标、元素类型和阅读顺序,以此作为后续生成的结构先验。坐标采用 COORD_0 ~ COORD_999 单 token 编码,相比传统三位数字序列,布局分析输出长度减少约 50%,推理延迟降低约 30%。这一设计使端到端模型在需要空间定位的场景(如合同关键字段抽取、多栏报纸排版)中补回了传统流水线的核心优势。
架构组成:视觉侧采用基于 AnyResolution 设计的 Qianfan-ViT,支持最高 4K 分辨率输入;语言侧使用 Qwen3-4B(32K 上下文,GQA 注意力),两者通过轻量 MLP 适配器对齐。训练分三阶段:先只训练适配器做跨模态对齐,再全参数微调,最后进行任务特化。
基准表现:在 OmniDocBench v1.5 上,Qianfan-OCR 以 93.12% 的综合得分排名端到端模型第一,并首次在多项子任务上超过 PaddleOCR-VL 等传统流水线系统。表格 TEDS 指标也显著优于同参数量级的通用 VLM(如 Qwen-VL)。
工程价值:4B 的参数规模使其推理成本仅为 7B+ 通用模型的三分之一左右,更适合企业级高并发文档处理场景。Layout-as-Thought 作为可选的慢思考开关,让用户在速度与精度之间自由权衡,是一个值得关注的 inference-time 工程思路。
Kinema4D:用运动学约束驱动的 4D 生成模型,推进具身仿真的真实感边界

核心动机:现有基于视频生成的机器人仿真器(如 UniSim、IRASim)大多在 2D 像素空间建模,或仅依赖语言指令表达动作意图。这两种方式都缺乏对机器人与环境之间真实 4D 时空交互的精确表达——碰撞形变、被遮挡物体的动态、跨时间帧的几何一致性,都无法在纯 2D 框架下得到有效约束。南洋理工大学和香港中文大学(深圳)联合提出的 Kinema4D,将仿真问题分解为机器人精确控制和环境生成式响应两个子问题分别建模。
方法拆解:(1) 精确 4D 机器人表示——基于 URDF 格式的机器人模型,通过正向运动学计算出每一时刻的关节姿态,生成精确的 4D 控制轨迹,完全绕开语义指令的模糊性。(2) 生成式 4D 环境建模——将 4D 机器人轨迹投影为 pointmap(逐帧点云图),作为空间-时间视觉信号注入生成模型,驱动模型在 RGB 图像序列和 pointmap 序列上同步生成环境的动态响应(物体形变、推移、抓取后轨迹等)。
数据集 Robo4D-200k:为支撑训练,团队构建了包含 201,426 个机器人交互片段、带高质量 4D 标注的大规模数据集,是目前已知规模最大的 4D 机器人交互数据集之一,涵盖多种机器人形态和操作场景。
关键实验结论:Kinema4D 能准确模拟材质形变(如柔性物体被抓取时的变形)、被遮挡物体的动态(机械臂移开后物体的重新出现),以及跨多个时间步的几何一致性。实验还展现了零样本迁移潜力——在未见过的机器人形态(embodiment-agnostic)上仍能生成物理合理的交互序列,这对于降低仿真到现实迁移代价具有实际意义。
研究意义:Kinema4D 的核心贡献在于将运动学约束与生成式世界模型显式解耦,避免了端到端黑盒学习中控制信号与环境响应相互纠缠的问题。对具身智能研究者而言,这一思路可以作为构建更可控、更可解释的仿真数据飞轮的参考框架。
视频扩散模型的推理机制:不是帧间推理,而是去噪步骤间推理
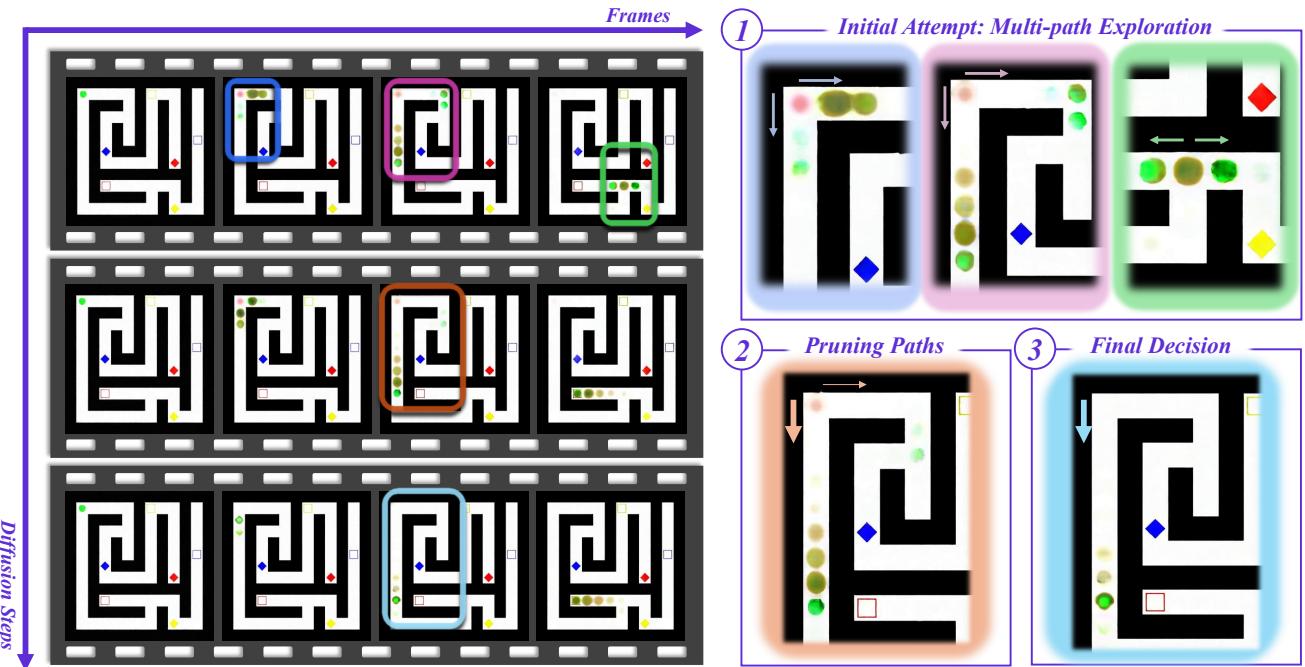
扩散视频模型展现出令人意外的推理能力,比如让模型生成走迷宫的视频,它真的能找到正确路径。此前学界普遍认为这种推理能力来源于帧间时序推进(Chain-of-Frames,CoF)——即推理过程随视频帧逐步展开,类似思维链在帧序列上的延伸。
本文来自 SenseTime Research、南洋理工、UCB、UCSD 和 CMU 的联合团队,通过系统性消融实验推翻了 CoF 假设,提出了全新机制:Chain-of-Steps(CoS)。研究发现,推理过程主要沿扩散去噪步骤发展,而非沿时间轴帧序列。在早期去噪步骤中,模型同时探索多条候选解(如迷宫中多条路径并行生成),经中间步骤逐步剪枝,最终在后期步骤收敛到唯一答案。
论文进一步识别出三类关键涌现行为:(1)工作记忆:模型能在去噪过程中持续引用先前状态;(2)自我纠错与增强:中间步骤能识别并修复错误路径;(3)感知先于行动:早期步骤建立语义锚定,后期步骤执行结构化操作。
在 DiT 架构层面,作者还发现了功能自分化现象:浅层负责密集感知特征编码,中间层执行实际推理,深层负责表征整合收敛。基于此洞察,作者提出一种无需训练的推理增强策略:对不同随机种子下相同模型的潜变量轨迹进行集成,即可提升推理准确率。
这项工作为将视频生成模型作为新型推理底座提供了机制层面的理论基础,也为后续改进视频推理能力提供了可操作的研究方向。
WorldCam:用相机位姿统一动作控制与三维一致性的交互式游戏世界模型
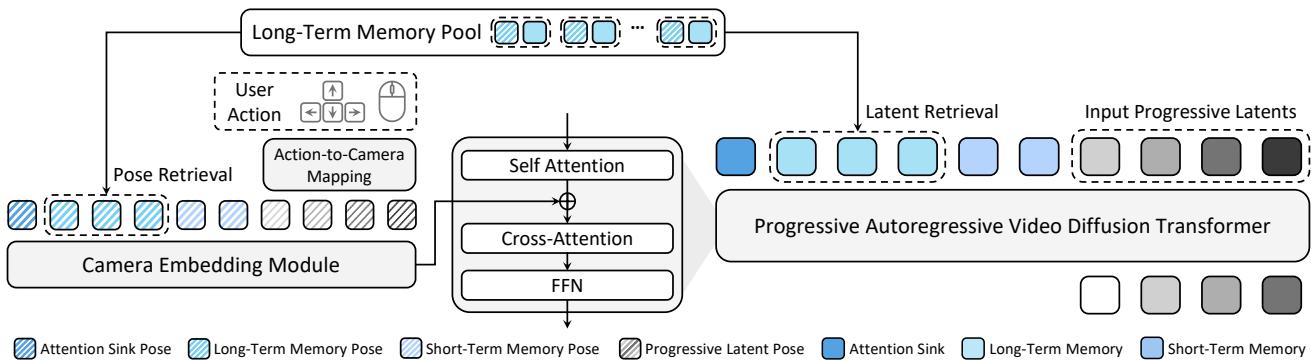
交互式游戏世界模型的目标是让用户能像玩游戏一样在生成的环境中自由探索。现有方法的主要瓶颈有两个:精确动作控制失准和长时序三维一致性崩溃。根本原因在于,前人将用户操作(键鼠输入)视为抽象条件信号直接注入模型,忽视了动作与三维世界之间的几何耦合本质:每次操作本质上是相机在三维场景中的相对运动,这些运动累积形成全局相机轨迹,决定了三维场景如何投影到二维画面。
本文来自 KAIST、Adobe Research 和 MAUM AI 的联合团队,提出以相机位姿作为统一几何表示,同时解决动作控制与三维一致性两个问题。技术上有两个核心设计:
第一,将用户输入通过李代数(Lie algebra)表示为精确的 6-DoF 相机位姿,经相机嵌入器注入生成模型,实现物理意义明确的动作对齐。
第二,利用全局相机位姿作为空间索引,在长时序导航中检索历史观测帧,确保重访同一地点时视觉内容几何一致,解决了长程漫游中场景漂移的问题。
为支撑研究,团队构建了一个包含 3000 分钟真实游戏录像的大规模数据集,每段视频均标注了相机轨迹与文本描述。实验表明,WorldCam 在动作可控性、长时序视觉质量和三维空间一致性上均显著超越现有方法。
该工作的意义在于:将经典三维视觉中的相机位姿表示引入视频生成,为构建具有物理正确性的可交互世界模型提供了一条更扎实的几何路径。
TRUST-SQL:面向未知数据库 Schema 的多轮强化学习 Text-to-SQL
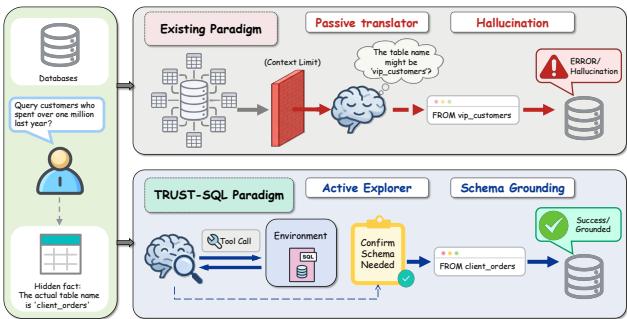
Text-to-SQL 领域长期依赖一个隐含前提——完整数据库 Schema 已预先注入上下文。然而在真实企业环境中,数据库往往包含数百张表、大量噪声元数据,且持续动态变化。把完整 Schema 塞进有限的上下文窗口不仅低效,还会因无关表干扰导致模型性能下降。
本文提出 TRUST-SQL(Truthful Reasoning with Unknown Schema via Tools),正式定义了"未知 Schema 场景":Agent 需要像真实 DBA 一样,主动探索数据库、按需检索元数据,而非被动接收完整 Schema。任务被建模为部分可观测马尔可夫决策过程 POMDP。
核心设计是结构化的四阶段交互协议:Explore(探索表结构)→ Propose(提出候选表假设)→ Generate(生成 SQL)→ Confirm(执行验证)。其中 Propose 阶段充当强制认知检查点,迫使模型在生成 SQL 前显式锁定所依赖的表集合,有效防止模型在长上下文中"幻想"不存在的字段。
训练策略上,作者提出 Dual-Track GRPO:通过 token 级掩码优势函数,将 Schema 探索奖励与 SQL 执行结果奖励解耦,解决长轨迹信用分配问题,较标准 GRPO 取得 9.9% 相对提升。
实验在五个基准上评测 4B 和 8B 两种规模模型,平均绝对提升分别达 30.6% 和 16.6%,且在完全不预载元数据的条件下,性能持平甚至超越依赖 Schema 预填充的强基线。这表明 TRUST-SQL 具备实际部署价值,尤其适合企业级复杂数据库场景。
LEAD:利用潜在熵感知解码缓解多模态推理模型幻觉
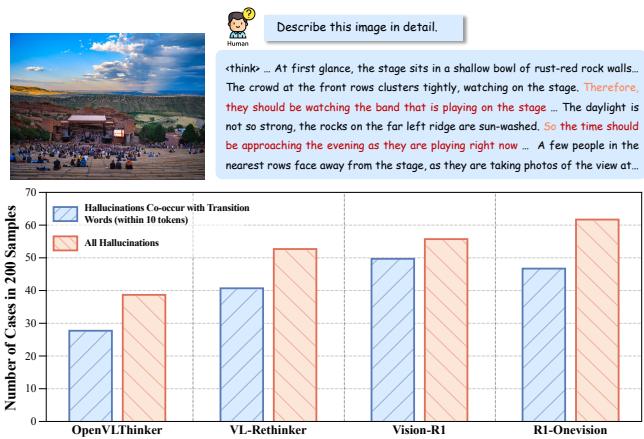
多模态大型推理模型(MLRMs)在视觉问答上取得显著进展,但幻觉问题依然顽固。本文提供了一个关键观察:在推理链中,转折性连词(because、however、wait 等)出现时往往伴随着较高的 token 熵,而这些高熵位置正是幻觉内容高发的节点。
传统应对幻觉的方法依赖视觉奖励重设计或数据增强,代价高昂。作者受叠加表征理论启发,提出:模型过度依赖离散 token 序列推理,在高熵阶段会忽视上下文密集语义线索。因此,直接从 token 概率分布中提取丰富语义信息是更高效的路径。
基于此,提出 LEAD(Latent Entropy-Aware Decoding)——一种无需训练的即插即用解码策略。其核心是熵感知推理模式切换:在高熵阶段,模型以概率加权连续嵌入(latent superposed representation)替代离散 token,整合多个候选语义;当熵回落时,自动切换回标准离散 token 解码。此外还引入先验引导视觉锚点注入策略,显式增强视觉信息在高不确定阶段的影响力,防止模型在推理过程中忽略图像信息。
LEAD 的优势在于不修改模型权重,可直接挂载到任意 MLRM 上。在多个多模态幻觉评测基准上的实验表明,LEAD 有效降低了幻觉率,为推理模型解码阶段的不确定性管理提供了一条轻量级的可行路径。
让大模型从真实部署经验中持续学习:在线经验学习框架 OEL
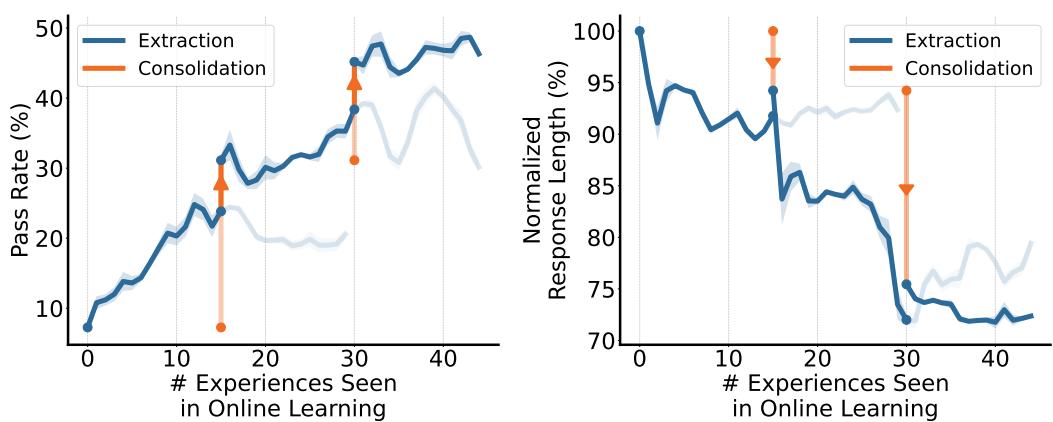
当前大语言模型的主流改进范式依赖离线训练,收集人工标注数据或在模拟环境中做强化学习。模型一旦部署,就成了一个静态工件,与用户的海量真实交互完全被丢弃,形成了难以突破的数据瓶颈。微软研究院提出的 OEL(Online Experiential Learning) 框架,正是为了打破这一困局。
OEL 的核心思路分为两个交替迭代的阶段:第一阶段,从用户侧部署期间收集的交互轨迹中,提取可迁移的"经验知识"(experiential knowledge)——即对任务规律的归纳总结,而非原始轨迹本身;第二阶段,通过在策蒸馏(on-policy context distillation),将这些知识内化到模型参数中,且服务端无需访问用户侧环境。两阶段循环迭代,形成一个真正意义上的在线学习闭环。
关键亮点在于整个流程完全无奖励函数:不需要奖励模型、不需要可验证的奖励信号、也不需要人工标注。模型仅凭环境返回的文本反馈(如错误描述、状态变化)就能自我进化。实验在文本游戏(text-based game)环境上跨多个模型规模验证,结果显示 OEL 在每轮迭代后任务通过率和 token 效率双双提升,同时保持分布外泛化性能不退化。
研究进一步表明:提炼后的经验知识远比原始轨迹更有效,且知识来源与策略模型之间的在策一致性是有效学习的关键。这一框架为让 LLM 在生产环境中自我进化提供了一条无需环境权限、无需标注的可行路径。
FinToolBench:首个面向真实金融工具调用的 LLM Agent 评测基准
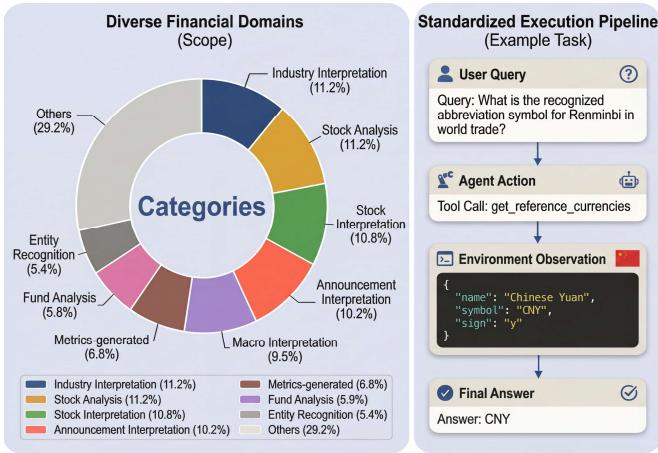
随着 LLM Agent 被越来越多地部署在金融场景中,一个核心问题浮现:现有评测基准根本无法反映金融工具调用的真实难度。现有金融 benchmark 大多停留在静态文本分析或文档问答,而通用工具 benchmark 又缺乏金融领域特有的合规性与数据时效性约束。上海人工智能实验室等机构联合提出的 FinToolBench 正是为了填补这一空白。
FinToolBench 构建了一个真实可执行的金融生态系统:覆盖 760 个可运行金融 API,配套 295 道需调用工具才能作答的查询,横跨行情数据、监管文件、宏观经济指标等多个领域。评测框架突破了简单的"API 调用是否成功"二元判断,重点考察三个金融特有维度:
- 时效性(Timeliness):询问"当前汇率"时,若 Agent 返回日线快照而非实时数据,即视为错误;
- 意图克制(Intent Restraint):Agent 必须严格区分查询型与交易型操作,避免越权执行;
- 监管域对齐(Regulatory Domain Alignment):工具调用须符合对应市场的合规约束。
论文同时提出基线方法 FATR(Finance-Aware Tool Retrieval),通过金融感知的检索与推理机制提升 Agent 的稳定性与合规性。评测结果揭示:即便是顶级 LLM,在金融工具调用场景下的合规通过率也显著低于通用场景,时效性判断和意图边界识别是最主要的失败模式。
FinToolBench 的工具清单、执行环境及评测代码均将开源,为构建可审计、可信赖的金融 AI Agent 提供了迄今最贴近真实业务的测试平台。
其余论文速览 · #11–52
| # | 论文 | 领域 | Votes |
|---|---|---|---|
| 11 | WiT: Waypoint Diffusion Transformers via Trajector | 自动驾驶 | 28 |
| 12 | Rethinking UMM Visual Generation: Masked Modeling | 视觉生成 | 26 |
| 13 | MEMO: Memory-Augmented Model Context Optimization | 长上下文 | 19 |
| 14 | GradMem: Learning to Write Context into Memory wit | 长上下文 | 19 |
| 15 | SegviGen: Repurposing 3D Generative Model for Part | 3D 分割 | 15 |
| 16 | AgentProcessBench: Diagnosing Step-Level Process Q | Agent 评测 | 14 |
| 17 | SocialOmni: Benchmarking Audio-Visual Social Inter | 社交 AI | 13 |
| 18 | SWE-Skills-Bench: Do Agent Skills Actually Help in | Agent 评测 | 12 |
| 19 | Efficient Reasoning on the Edge | 边缘推理 | 11 |
| 20 | SparkVSR: Interactive Video Super-Resolution via S | 视频超分 | 10 |
| 21 | One-Eval: An Agentic System for Automated and Trac | 自动化评测 | 9 |
| 22 | Semi-Autonomous Formalization of the Vlasov-Maxwel | 定理证明 | 8 |
| 23 | M^3: Dense Matching Meets Multi-View Foundation Mo | 3D 匹配 | 7 |
| 24 | Reliable Reasoning in SVG-LLMs via Multi-Task Mult | SVG 推理 | 7 |
| 25 | Omnilingual MT: Machine Translation for 1,600 Lang | 机器翻译 | 6 |
| 26 | SK-Adapter: Skeleton-Based Structural Control for | 骨骼控制 | 5 |
| 27 | From Passive Observer to Active Critic: Reinforcem | 强化学习 | 5 |
| 28 | Recursive Language Models Meet Uncertainty: The Su | 递归模型 | 4 |
| 29 | FlashSampling: Fast and Memory-Efficient Exact Sam | 高效采样 | 3 |
| 30 | Sparking Scientific Creativity via LLM-Driven Inte | 科研创意 | 2 |
| 31 | MolmoB0T: Large-Scale Simulation Enables Zero-Shot | 机器人 | 2 |
| 32 | V-Co: A Closer Look at Visual Representation Align | 视觉表征 | 2 |
| 33 | Mixture of Style Experts for Diverse Image Styliza | 风格迁移 | 2 |
| 34 | ViT-AdaLA: Adapting Vision Transformers with Linea | ViT 适配 | 2 |
| 35 | SuperLocalMemory V3: Information-Geometric Foundat | 记忆架构 | 1 |
| 36 | ECG-Reasoning-Benchmark: A Benchmark for Evaluatin | ECG 推理 | 1 |
| 37 | CCTU: A Benchmark for Tool Use under Complex Const | 工具约束 | 1 |
| 38 | Anticipatory Planning for Multimodal AI Agents | 多模态规划 | 1 |
| 39 | Learning Human-Object Interaction for 3D Human Pos | 人体姿态 | 1 |
| 40 | Polyglot-Lion: Efficient Multilingual ASR for Sing | 多语言 ASR | 1 |
| 41 | OneWorld: Taming Scene Generation with 3D Unified | 3D 生成 | 1 |
| 42 | MDM-Prime-v2: Binary Encoding and Index Shuffling | 二进制编码 | 1 |
| 43 | Residual Stream Duality in Modern Transformer Arch | 残差分析 | 1 |
| 44 | Theoretical Foundations of Latent Posterior Factor | 后验因子 | 1 |
| 45 | I Know What I Don't Know: Latent Posterior Factor | 后验因子 | 1 |
| 46 | Test-Time Strategies for More Efficient and Accura | Agent 测试 | 0 |
| 47 | Chain-of-Trajectories: Unlocking the Intrinsic Gen | 轨迹生成 | 0 |
| 48 | BERTology of Molecular Property Prediction | 分子预测 | 0 |
| 49 | VAREX: A Benchmark for Multi-Modal Structured Extr | 结构抽取 | 0 |
| 50 | HistoAtlas: A Pan-Cancer Morphology Atlas Linking | 病理图谱 | 0 |
| 51 | ARISE: Agent Reasoning with Intrinsic Skill Evolut | Agent 进化 | 0 |
| 52 | Measuring Primitive Accumulation: An Information-T | 信息论 | 0 |
今日趋势
- 工业代码智能专业化:InCoder-32B 以 32B 参数专攻 CUDA/RTL/嵌入式五大工业场景,将通用模型 28.8% 的瓶颈突破到工业可用级别,代码模型从"通用编程助手"向"领域专用专家"演进的趋势正在加速。
- 验证式推理成为 Agent 新范式:MiroThinker-H1 将验证机制内嵌推理链,局部修正 + 全局审计让深度研究 Agent 达到 SOTA,"生成更多 token"的暴力扩展路线正被"验证每一步 token"的精细化路线所取代。
- 视频生成可解释性突破:Chain-of-Steps 推翻帧间推理假说,证明推理能力沿去噪步骤而非时间轴涌现,为视频扩散模型的推理增强和架构优化提供了新的理论基础。
今天值得持续关注的三个方向:
1. 工业代码智能:InCoder 证明通用模型远不够用,领域专用训练仍是刚需
2. 验证式推理:MiroThinker 的内嵌验证机制可能成为下一代推理模型的标配
3. 世界模型的精确控制:WorldCam 和 Kinema4D 都在解决同一个问题——如何让生成模型"物理可信"
今天的内容就到这里,如果觉得有帮助,顺手 点赞、在看、转发 支持一下 🙏 记得 星标 ⭐ 公众号,不错过每日论文精选,明天继续 👋
© 2026 AI Insight · 机智流 · 本文由 AI 生成,可能有误
参考来源
- InCoder-32B — huggingface.co/papers/2603.16790
- MiroThinker-H1 — huggingface.co/papers/2603.15726
- Qianfan-OCR — huggingface.co/papers/2603.13398
- Kinema4D — huggingface.co/papers/2603.16669
- 视频扩散推理机制(Chain-of-Steps) — huggingface.co/papers/2603.16870
- WorldCam — huggingface.co/papers/2603.16871
- TRUST-SQL — huggingface.co/papers/2603.16448
- LEAD — huggingface.co/papers/2603.13366
- OEL(在线经验学习) — huggingface.co/papers/2603.16856
- FinToolBench — huggingface.co/papers/2603.08262