速览目录 · Top 10
| # | 论文 | 领域 | Votes |
|---|---|---|---|
| 1 | Scientific Taste | AI 科研 / 元研究 | 214 |
| 2 | OpenSeeker | 搜索 Agent / 开源 | 123 |
| 3 | EnterpriseOps-Gym | Agent / 评测基准 | 113 |
| 4 | HSImul3R | 具身智能 / 3D 重建 | 91 |
| 5 | Seoul World Model | 视频生成 | 90 |
| 6 | AttnRes | LLM 架构 | 55 |
| 7 | MoDA | 大模型架构 | 45 |
| 8 | xLSTM 蒸馏 | 大模型架构 | 28 |
| 9 | CAD (VLM 幻觉诊断) | 多模态 | 24 |
| 10 | ViFeEdit | 视频生成 | 19 |
今日主线一:AI 元研究的突破——复旦团队让 AI 学会判断论文潜在影响力,Scientific Judge 超越 GPT-5.2 和 Gemini 3 Pro,这标志着 AI 从"写论文"进化到"评论文"。主线二:开源 Agent 全面崛起——OpenSeeker 仅用 11,700 条合成数据训练出 30B 搜索 Agent,在 BrowseComp 上以 29.5% 大幅领先第二名(15.3%),全栈开源。主线三:注意力机制的深层革新——Kimi 的 AttnRes 和字节的 MoDA 分别从残差路径和跨层检索两个角度重新设计深层 Transformer。
Insight:当 AI 开始具备"科研品味",下一个被革新的不只是论文写作,而是整个科研评审体系——从同行评议到基金评审都将面临范式转换。
Scientific Taste: 用强化学习让 AI 学会判断论文潜在影响力
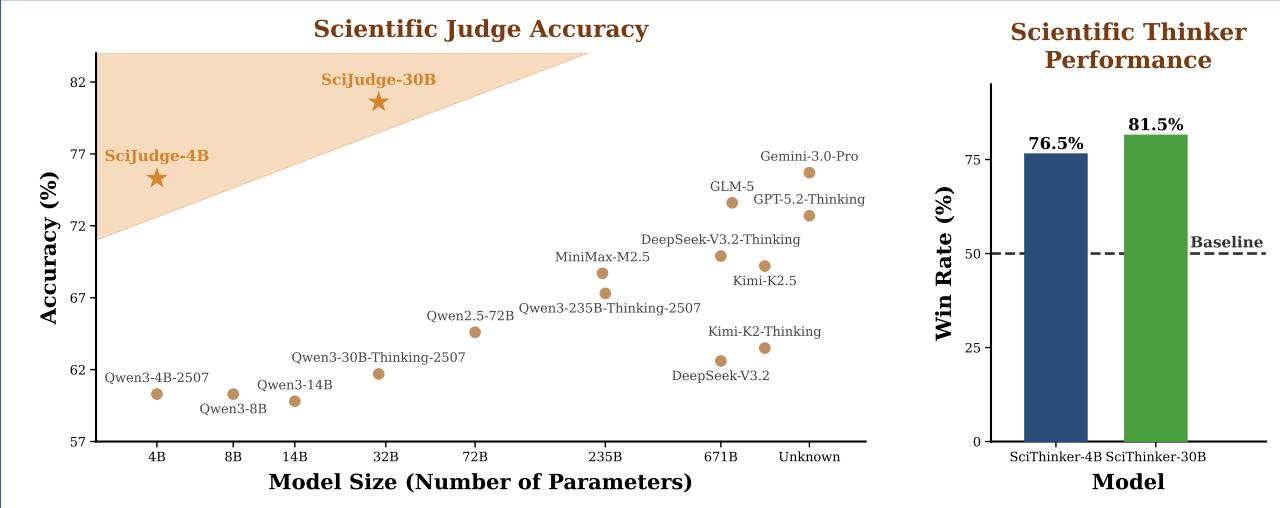
顶尖科学家不只擅长执行研究,更具备一种难以言传的「科学品味」——判断哪个研究方向值得追,哪篇 idea 有真正的影响力。这种能力此前被认为只属于人类专家,而本文来自复旦大学的团队尝试将其系统化、可学习化。
核心动机:现有 AI 科学家研究大多聚焦于「执行能力」(如文献检索、自动实验),对 AI 如何判断研究价值这一上游问题几乎空白。论文指出,引用数是社区对研究价值的长期集体反馈,可以作为偏好信号的代理。
方法框架 RLCF(Reinforcement Learning from Community Feedback):研究分两个模块。首先训练 Scientific Judge,基于 70 万对「高引 vs 低引」论文摘要对(按领域和发表时间严格匹配)进行偏好建模,让模型学会从 abstract 层面判断哪篇论文更有影响力潜力。随后以 Scientific Judge 作为奖励模型,通过强化学习训练 Scientific Thinker,使其提出的 research idea 分布朝高影响力方向对齐。
关键结果:Scientific Judge 在 SciJudgeBench 上超越 GPT-5.2、Gemini 3 Pro 等闭源旗舰模型,且泛化到未见领域、未来年份测试集和同行评审偏好场景。Scientific Thinker 生成的 idea 在集成评估下胜过未对齐基线模型的胜率显著提升。
一句话总结:用 70 万对高低引用论文作偏好数据,通过 RLCF 两阶段训练,首次系统验证了 AI 可以习得「科学品味」并将其迁移到 idea 生成中。
OpenSeeker: 全开源训练数据驱动的前沿级搜索 Agent
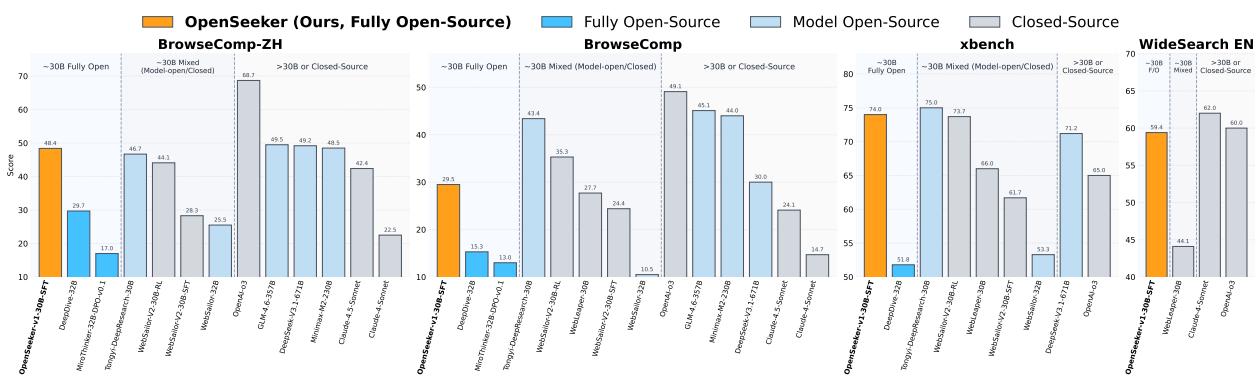
深度搜索能力正成为前沿 LLM Agent 的标配,但高性能搜索 Agent 的训练数据长期被工业界垄断,开源社区缺乏完整的可复现路径。上海交通大学团队推出 OpenSeeker,将模型权重、训练数据、合成 pipeline 全部开放,试图打破这一壁垒。
核心动机:BrowseComp 基准上,截至 2025 年 4 月即便最强闭源模型也难超 10 分;到 2026 年 3 月已有超过 10 个 Agent 突破 50 分。然而这些高分 Agent 几乎全部来自有充裕算力的大厂,训练数据从未公开。OpenSeeker 针对这一「数据黑箱」问题切入。
两项核心技术:(1)基于事实的可控 QA 合成:通过拓扑展开(topological expansion)和实体混淆(entity obfuscation)对 Web 图谱进行逆向工程,自动生成复杂度和覆盖度可控的多跳推理问题,从根本上解决数据稀缺问题。(2)去噪轨迹合成:引入回顾式摘要机制(retrospective summarization),对 teacher LLM 生成的搜索轨迹进行噪声过滤,显著提升动作序列质量,使 SFT 训练更有效。
关键结果:OpenSeeker(30B,仅 11,700 条合成样本 + 单次 SFT 训练)在 BrowseComp、BrowseComp-ZH、xbench-DeepSearch、WideSearch 四个基准上均达到 SOTA 开源水平。BrowseComp 上以 29.5% 大幅领先第二名全开源 Agent DeepDive(15.3%),BrowseComp-ZH 上甚至超越经过持续预训练 + SFT + RL 的通义 DeepResearch(48.4% vs 46.7%)。
一句话总结:用不到 1.2 万条合成训练样本 + 单次 SFT,OpenSeeker 实现了对工业界闭源搜索 Agent 的比肩乃至超越,并将完整数据和权重开源,为搜索 Agent 研究提供了可复现的基准起点。
EnterpriseOps-Gym:企业级有状态智能体规划与工具调用基准测试
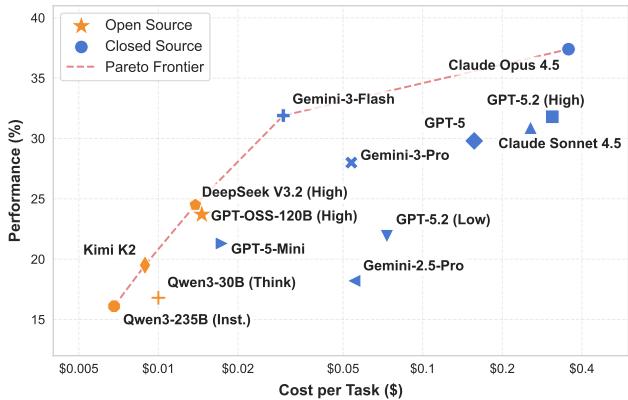
当前 AI Agent 的企业落地面临一个根本性矛盾:现有评测基准过于简化,根本无法反映真实业务场景的复杂性。EnterpriseOps-Gym 正是为填补这一空白而生。
基准设计:研究团队构建了一个容器化沙盒环境,内含 164 张数据库表和 512 个可调用工具,跨越客服、HR、IT 等 8 大业务领域,共设计 1,150 道专家级任务。与 SWE-bench 等代码基准不同,这里的任务要求 Agent 在有持久状态变更的环境中维持多步骤计划,并严格遵守访问控制策略——这正是企业真实工作流的核心挑战。
核心发现令人警醒:对 14 个前沿模型的测评显示,最强的 Claude Opus 4.5 成功率仅为 37.4%,开源模型普遍低于 20%。更关键的发现是:当提供人工编写的「Oracle 计划」后,成功率提升 14–35 个百分点,这直接指向了模型的战略推理能力是当前瓶颈所在,而非工具调用能力本身。
另一个高风险问题是拒绝不可行任务的能力——最佳模型也只有 53.9% 的正确拒绝率。这意味着近半数情况下,Agent 会在无法完成的任务上执行错误操作,直接修改数据库或触发下游流程,产生难以逆转的副作用。
对企业部署的启示:研究清晰地表明,当前 Agent 尚不具备在企业环境中完全自主运行的能力。EnterpriseOps-Gym 为研究界提供了一个可复现的压力测试平台,指引未来工作聚焦于长程规划和策略合规两大方向。
HSImul3R:物理仿真驱动的人-场景交互三维重建框架

从视频或图片重建人与场景的交互过程,是具身机器人训练数据获取的核心难题。现有方法普遍存在「视觉可信、物理失效」的困境:重建结果看起来合理,但一旦导入物理引擎,人物就会穿墙、漂浮或倒塌。HSImul3R 提出了一套以物理仿真器为核心监督信号的双向优化框架,直接攻克这一感知-仿真鸿沟。
核心架构——双向优化:框架分为两个互补方向。正向优化在固定场景几何的前提下,采用「场景靶向强化学习」来精炼人体运动,同时以运动保真度和接触稳定性作为双重奖励信号,确保脚步不悬空、手部真实触碰物体。反向优化则创新性地引入「直接仿真奖励优化(DSRO)」,利用仿真器对重力稳定性和交互成功率的反馈,反过来修正场景几何——物体的形状和位置会被迭代调整,直到满足物理约束。
数据来源灵活:HSImul3R 同时支持稀疏视角图片和单目视频作为输入,借助图像到三维生成模型建立度量一致的初始对齐,降低了数据采集门槛,方便在野外环境中收集真实人类行为。
实验证明,HSImul3R 生成的重建结果可以直接部署到真实人形机器人,完成搬运、坐立等复杂动作,是当前少数能真正打通「感知重建→物理仿真→机器人部署」完整链路的工作之一。
将世界仿真模型锚定到真实城市:首尔世界模型
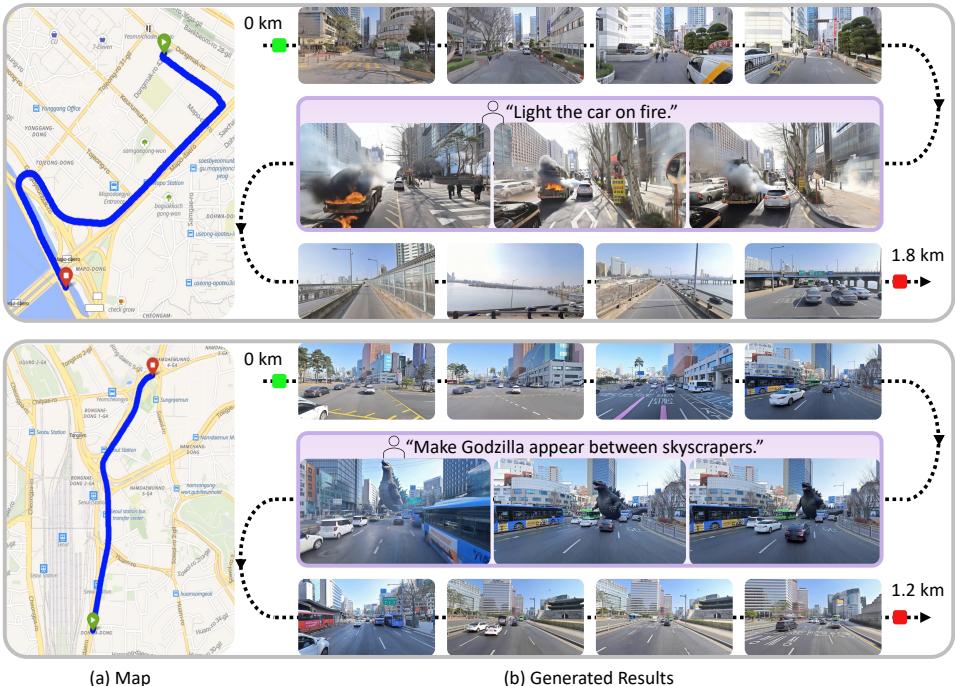
大多数视频世界模型生成的都是"虚构环境"——给定一张起始图,后续所有内容由模型凭空想象。KAIST AI 与 NAVER AI Lab 合作提出的 Seoul World Model(SWM) 反其道而行:让世界模型生成的是真实存在的首尔街道,而非杜撰出来的城市景观。
核心方案是检索增强条件生成(RAG-conditioned generation)。给定 GPS 坐标、摄像机动作和文字提示,SWM 从街景图库中检索附近的参考图,将几何结构与外观信息注入自回归视频生成过程,使每段生成内容都锚定在真实地理位置的布局之上。模型在 44 万张首尔街景图、真实驾驶视频和合成城市数据上微调一个预训练视频世界模型。
引入真实街景带来三个技术难点,论文逐一给出解法:时序错位(检索到的旧图与动态目标场景不一致)→ 跨时间配对训练策略;轨迹多样性不足与数据稀疏(车载采集间隔大)→ 构建大规模合成数据集 + 视角插值流水线;长程生成飘移 → 提出 Virtual Lookahead Sink,每段生成前持续将未来位置的检索图作为锚点重新校准。
在首尔、釜山和 Ann Arbor 三座城市的评测中,SWM 在空间保真度、时序一致性和长程稳定性上均优于现有视频世界模型,可沿数百米轨迹生成与真实城市高度吻合的视频,同时支持多样化摄像机运动和文字驱动的场景变换(如洪水、黄昏光效)。
注意力残差:用深度维注意力替代固定残差累加
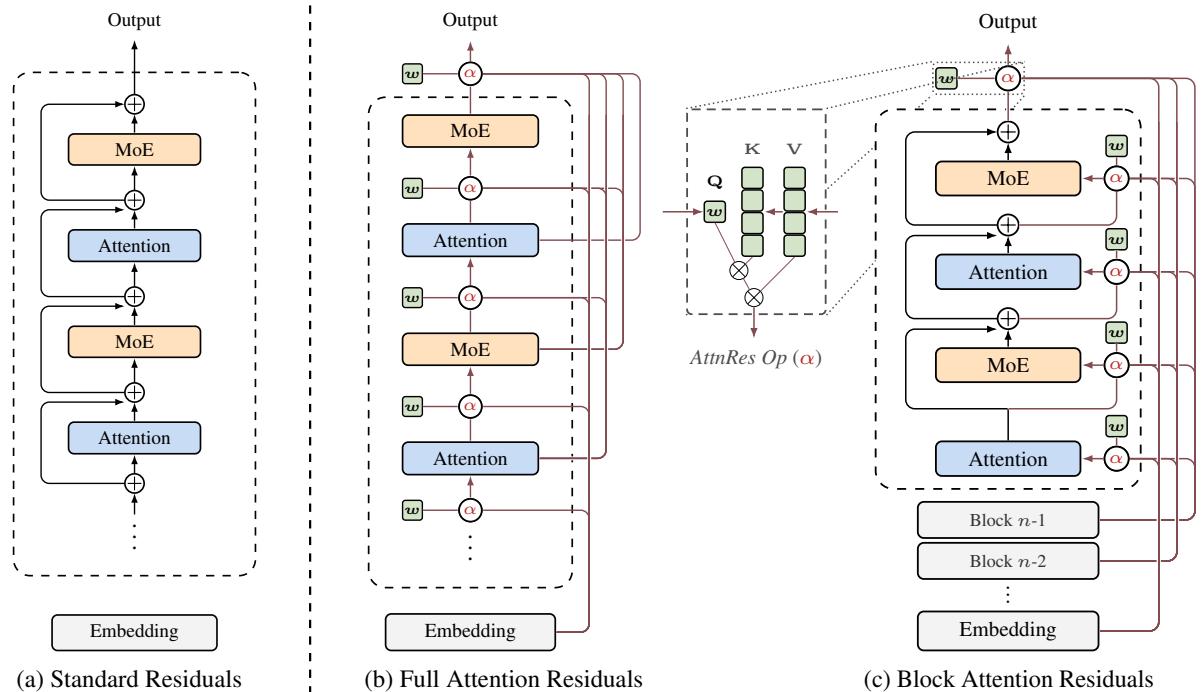
现代大语言模型中,残差连接(Residual Connection)与 PreNorm 几乎是标配,但它们始终以固定单位权重对所有层的输出做均匀累加。Kimi 团队发现这种均匀聚合会导致隐藏状态随深度以 O(L) 速度增长,越深的层对最终表示的贡献越被稀释,早期层的信息无法被选择性地取用——这正是大量层可以被无损剪枝的根本原因。
论文提出 Attention Residuals(AttnRes),用深度维度上的 softmax 注意力替换固定累加。具体而言,每层用一个可学习的伪查询向量(d 维)对前面所有层的输出计算注意力权重,使当前层能够内容感知地、动态地从历史各层中选择性聚合信息。作者指出这与 RNN 在序列维度遇到问题后引入注意力机制的情形在形式上完全对称。
面向大规模训练的工程挑战,论文进一步提出 Block AttnRes:将层分组为若干 Block,仅在 Block 级表示上做注意力,把内存开销从 O(Ld) 降至 O(Nd),同时结合基于缓存的流水线通信和两阶段计算策略,使其成为标准残差连接的即插即用替代方案,几乎无额外开销。
Kimi 团队将 AttnRes 集成进 Kimi Linear 架构(48B 总参数 / 3B 激活参数),在 1.4T token 上预训练验证:AttnRes 有效缓解了 PreNorm 稀释问题,使各层输出幅度和梯度分布更均匀,所有下游评测任务均有提升。Scaling law 实验也确认改进在不同模型规模下保持一致。
MoDA:混合深度注意力,让大模型深度扩展不再「信息稀释」
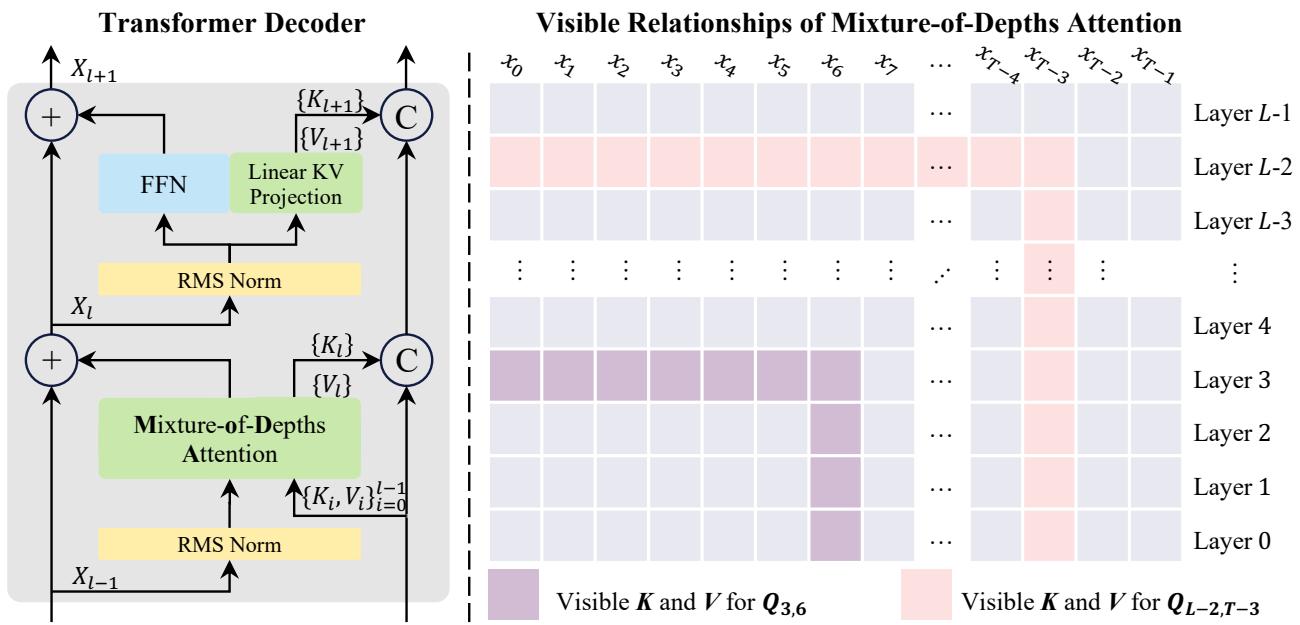
核心问题:深度扩展中的信息稀释
大语言模型扩展深度时存在一个长期困扰:浅层形成的有价值特征,在经过一层又一层的残差更新后会被逐渐"冲淡",到深层时已难以有效恢复。这本质上是残差路径的单轨制缺陷——所有历史信息都被压缩进一条隐状态轨迹,没有任何机制让深层直接"回望"浅层曾经存储的关键信息。
MoDA 的解决思路
来自字节跳动 Seed 与华中科技大学的团队提出了 混合深度注意力(MoDA)。其核心思想是:在标准的序列维度注意力基础上,同时允许每个注意力头跨层访问"深度 KV"——即同一序列位置在所有前驱层产生的 Key-Value 对。
这相当于把注意力机制从"序列内检索"扩展到了"深度维检索":模型不仅能在同一层内关注不同位置的 token,还能在同一位置回溯不同层深度上曾经编码过的特征,实现了 DenseNet 跨层连接的语义,但以注意力的数据驱动方式动态选择,而非固定稠密连接。
实验结果
在 1.5B 参数规模的模型上,MoDA 相比强基线(OLMo2)带来显著提升:
- 10 个验证集上平均困惑度降低 0.2
- 10 个下游任务平均性能提升 2.11%
- 额外计算开销仅 3.7% FLOPs
此外,MoDA 与 post-norm 组合时效果优于 pre-norm,这为架构选型提供了实用指导。代码已开源。
xLSTM 蒸馏新突破:Expert 合并让线性架构无损继承 Transformer 能力
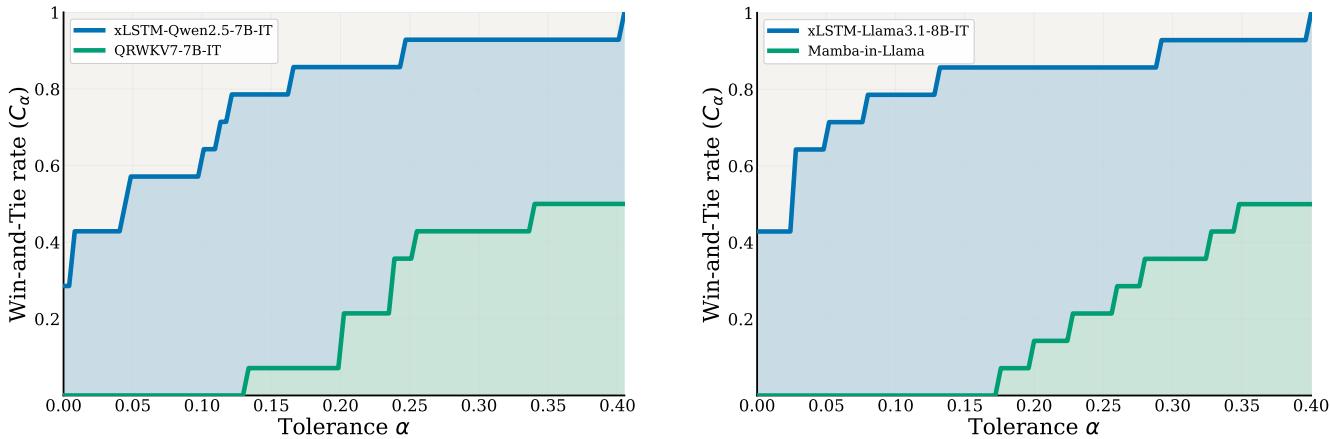
背景:线性化蒸馏的老大难问题
将 Transformer LLM 蒸馏成线性复杂度架构,是降低推理成本的重要路线。但长期以来,蒸馏出的学生模型总有一道坎迈不过去:在语言理解和知识类任务上勉强追平教师,一到数学推理、代码生成这类需要强生成能力的任务上就明显掉队。
关键创新:Expert 合并阶段
论文的核心贡献是在蒸馏流程中引入了一个额外的 Expert Merging 阶段:先对各层独立进行线性化专家训练,再将多个专家合并成单一模型。这种分治再合并的策略,让每个专家在局部优化时不受其他层干扰,合并后又能发挥协同效应,显著提升了学生模型在复杂生成任务上的表现。
实验覆盖与结果
团队以 xLSTM 作为学生架构,对 Llama、Qwen、OLMo 系列的 base 模型和指令微调模型进行蒸馏:
- xLSTM-Qwen2.5-7B-IT 和 xLSTM-Llama3.1-8B-IT 在数学、代码、STEM、对话等多个生成基准上达到或超越同类线性化方法的最佳基线
- 部分任务上学生模型甚至超越教师,验证了 xLSTM 线性架构本身的表达潜力
xLSTM 架构具备线性推理复杂度,在长序列上推理成本远低于 Transformer。本文将高性能 Transformer LLM 的知识有效迁移到 xLSTM,向"用更少能耗部署同等能力模型"这一目标迈出了重要一步。
解剖谎言:多阶段诊断框架追踪视觉语言模型幻觉根源

视觉语言模型(VLM)的幻觉问题一直是落地部署的核心障碍:模型会生成听起来合理但事实错误的内容。新加坡国立大学的研究团队提出了一个全新诊断范式,将幻觉从"静态输出错误"重新定义为"动态认知病理"。
核心发现:几何-信息对偶原理
论文最重要的理论贡献是发现了"几何-信息对偶"(geometric-information duality):在认知状态空间(Cognitive State Space)中,模型生成轨迹的几何异常与信息论意义上的高惊讶度(surprisal)在本质上是等价的。这意味着幻觉检测可以被优雅地转化为几何异常检测问题——不需要昂贵的标注数据,只需在低维空间中观察轨迹偏离。
三阶段诊断框架 CAD
研究设计了一套信息论探针,将模型生成过程映射到可解释的低维认知状态空间,并定义三类可测量的病理状态:
- 感知不稳定性(Perceptual Entropy, H_Evi):模型在证据生成阶段出现幻觉,如"看到"图中并不存在的摩托车
- 逻辑因果失败(Inferential Conflict, S_Conf):模型结论与自身证据自相矛盾,即"认知失调"
- 决策模糊性(Decision Entropy, H_Ans):最终答案阶段的不确定性过高
CAD 框架在 POPE(二元 QA)、MME(综合推理)、MS-COCO(开放字幕)三个基准上均达到最优性能,且在弱监督条件和含噪校准数据下依然鲁棒。代码已开源:github.com/Lexiang-Xiong/CAD
ViFeEdit:无需视频数据,仅用图像微调视频扩散 Transformer
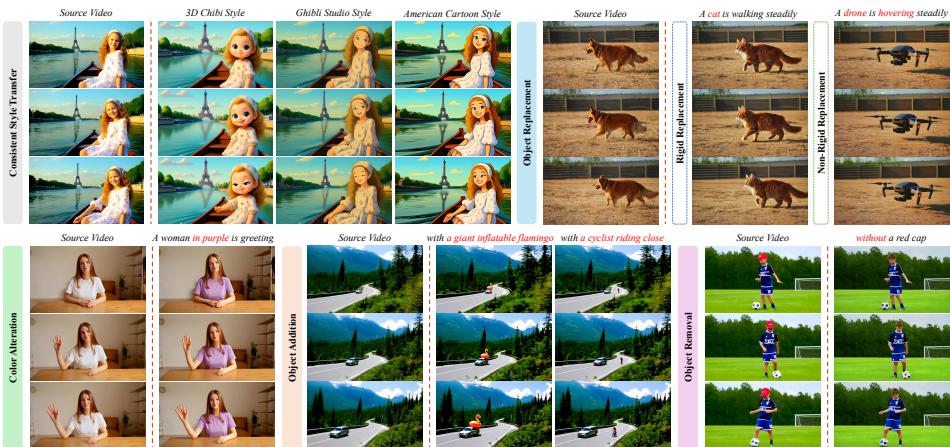
视频编辑模型的训练通常需要海量配对视频数据,构建成本动辄耗费一万 GPU 天以上。新加坡国立大学与上海交通大学的联合团队提出 ViFeEdit,一个无需任何视频训练数据、仅靠 2D 图像就能微调视频扩散 Transformer 的框架。
核心思路:解耦空间与时间建模
现代视频 DiT(如万象 Wan 系列)采用 3D 全注意力机制,同时处理空间和时间维度,导致无法直接用图像数据训练。ViFeEdit 的关键创新是一种架构重参数化(architectural reparameterization):将 3D 注意力中的空间独立性从时间维度中剥离出来,使调优器可以单独在 2D 图像上学习空间编辑行为,而预训练的时间模块保持冻结,继续维持帧间时序一致性。
双路径管线设计
ViFeEdit 采用双路径(dual-path)推理管线,为噪声调度配备独立的时间步嵌入,增强了对多种条件信号的适应性。同一个框架支持六类精细化视频编辑任务:
- 风格迁移 / 刚体替换 / 非刚体替换
- 颜色变换 / 对象添加 / 对象删除
这项工作的实用价值在于大幅降低视频编辑能力的获取门槛——中小团队无需搭建大规模 GPU 集群、无需收集配对视频,只需准备图像数据即可完成微调。代码已开源。
其余论文速览 · #11–46
| # | 论文 | 领域 | Votes |
|---|---|---|---|
| 11 | Safe and Scalable Web Agent Learning via Recreated | Agent 安全 | 18 |
| 12 | Make it SING: Analyzing Semantic Invariants in Cla | 对抗鲁棒 | 15 |
| 13 | TERMINATOR: Learning Optimal Exit Points for Early | CoT 优化 | 12 |
| 14 | WebVR: Benchmarking Multimodal LLMs for WebPage Re | 多模态评测 | 12 |
| 15 | Panoramic Affordance Prediction | 注意力机制 | 9 |
| 16 | Understanding Reasoning in LLMs through Strategic | MoE 架构 | 9 |
| 17 | FineRMoE: Dimension Expansion for Finer-Grained Ex | 光照编辑 | 9 |
| 18 | Learning Latent Proxies for Controllable Single-Im | 人体运动生成 | 8 |
| 19 | Riemannian Motion Generation: A Unified Framework | 多模态推理 | 8 |
| 20 | MMOU: A Massive Multi-Task Omni Understanding and | SFT vs RL | 7 |
| 21 | Supervised Fine-Tuning versus Reinforcement Learni | Coding Agent | 7 |
| 22 | Code-A1: Adversarial Evolving of Code LLM and Test | 视频检测 | 7 |
| 23 | Training-free Detection of Generated Videos via Sp | 随机优化 | 7 |
| 24 | POLCA: Stochastic Generative Optimization with LLM | Agent 竞技 | 6 |
| 25 | The PokeAgent Challenge: Competitive and Long-Cont | 遥感 | 6 |
| 26 | RS-WorldModel: a Unified Model for Remote Sensing | 视频推理 | 5 |
| 27 | VisionCoach: Reinforcing Grounded Video Reasoning | 视频生成 | 5 |
| 28 | FlashMotion: Few-Step Controllable Video Generatio | 文字渲染 | 4 |
| 29 | GlyphPrinter: Region-Grouped Direct Preference Opt | 知识图谱 | 4 |
| 30 | MoKus: Leveraging Cross-Modal Knowledge Transfer f | KV Cache | 3 |
| 31 | OxyGen: Unified KV Cache Management for Vision-Lan | LLM 动机 | 3 |
| 32 | Motivation in Large Language Models | 货币政策 | 3 |
| 33 | Mind the Shift: Decoding Monetary Policy Stance fr | 多 Agent | 3 |
| 34 | Autonomous Agents Coordinating Distributed Discove | Agent 评测 | 3 |
| 35 | EvoClaw: Evaluating AI Agents on Continuous Softwa | 具身操作 | 3 |
| 36 | Towards Generalizable Robotic Manipulation in Dyna | 数学发现 | 3 |
| 37 | HorizonMath: Measuring AI Progress Toward Mathemat | LLM 稀疏性 | 3 |
| 38 | When Does Sparsity Mitigate the Curse of Depth in | 文档解析 | 3 |
| 39 | Efficient Document Parsing via Parallel Token Pred | 扩散模型 | 3 |
| 40 | Spectrum Matching: a Unified Perspective for Super | 虚拟试穿 | 2 |
| 41 | Garments2Look: A Multi-Reference Dataset for High- | 概念分解 | 2 |
| 42 | SCoCCA: Multi-modal Sparse Concept Decomposition v | TTS | 2 |
| 43 | VoXtream2: Full-stream TTS with dynamic speaking r | 视频扩散 | 1 |
| 44 | Tri-Prompting: Video Diffusion with Unified Contro | 医疗 QA | 1 |
| 45 | sebis at ArchEHR-QA 2026: How Much Can You Do Loca | 图像 Token | 0 |
| 46 | SNCE: Geometry-Aware Supervision for Scalable Disc | 其他 | 0 |
今日趋势
- AI 元研究能力涌现:Scientific Taste 214 票断层领跑,标志着 AI 从「执行科研」迈向「评判科研」——用 70 万对高低引用论文训练出的 Scientific Judge 已超越 GPT-5.2 和 Gemini 3 Pro,同行评议系统将迎来深层冲击。
- 开源 Agent 全面比肩闭源:OpenSeeker 以仅 11,700 条合成数据、单次 SFT 在 BrowseComp 上以 29.5% 大幅领先第二名,全栈开源证明了「小数据+精工程」可以打败「大算力+黑箱」的研发路线。
- Transformer 深度扩展的架构革命:AttnRes(Kimi)和 MoDA(字节)同日登榜,分别从「残差路径动态化」和「跨层 KV 检索」两个角度重设计深层信息流,额外计算开销均在 4% 以内,是当前 LLM 架构创新最活跃的方向之一。
今天值得持续关注的三个趋势:
1. AI 科研元能力:从辅助写作到独立判断论文价值,AI 在科研生态中的角色正在升级
2. 注意力机制的深度革命:AttnRes 和 MoDA 表明,深层 Transformer 的信息流优化仍有巨大空间
3. 全开源 Agent 生态:OpenSeeker 证明开源数据+开源模型可以达到甚至超越闭源水平
感谢读到这里 如果觉得今天的论文解读有收获,欢迎 点赞、在看、转发 三连支持~想第一时间看到新推送,记得给公众号加个 星标,明天见
参考来源
- Scientific Taste — huggingface.co/papers/2603.14473
- OpenSeeker — huggingface.co/papers/2603.15594
- EnterpriseOps-Gym — huggingface.co/papers/2603.13594
- HSImul3R — huggingface.co/papers/2603.15612
- Seoul World Model — huggingface.co/papers/2603.15583
- AttnRes — huggingface.co/papers/2603.15031
- MoDA — huggingface.co/papers/2603.15619
- xLSTM 蒸馏 — huggingface.co/papers/2603.15590
- CAD (VLM 幻觉诊断) — huggingface.co/papers/2603.15557
- ViFeEdit — huggingface.co/papers/2603.15478