Perplexity:在 NVIDIA GB200 上服务 Qwen3 235B 后训练模型
Perplexity 公布在 GB200 NVL72 Blackwell 机柜上部署后训练 Qwen3 235B 的研究,证明 GB200 在大 MoE 高吞吐推理上对 Hopper 实现重大跨越,而非仅是训练平台。
查看原文TL;DR · 评测解读
Perplexity 单方面公布了 GB200 NVL72 推理 Qwen3 235B MoE 的数据,声称吞吐大幅超越 Hopper,但缺乏可复现的测试协议和公开基准数字。该宣示对采购决策有一定参考价值,但不能替代独立第三方评测。
深度解读
测了什么?
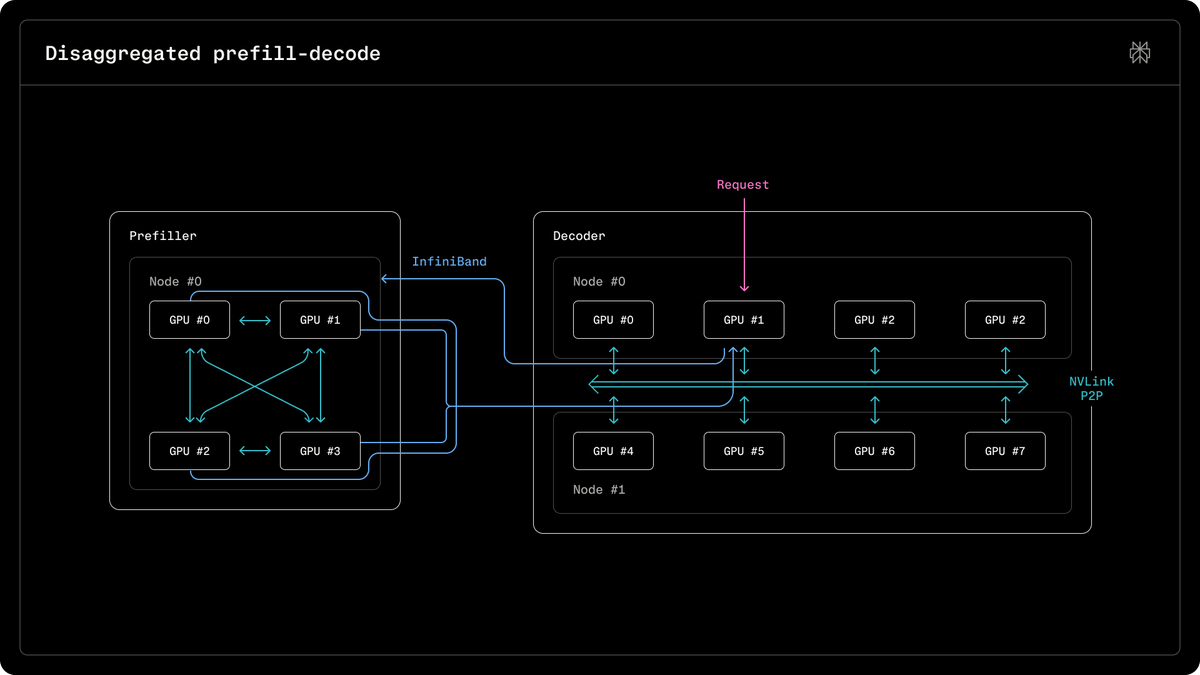
Perplexity 这条 tweet 披露的是:在 NVIDIA GB200 NVL72 机柜(72 颗 Blackwell GPU 互联)上部署Qwen3 235B MoE进行推理服务,核心论点是 GB200 不仅是训练平台,在大 MoE 模型的高吞吐推理场景下对 Hopper(H100/H200)实现了"重大跨越"。
但问题在于:这条 announcement 仅是一段文字声明,配图是一张性能曲线截图,没有任何公开的基准测试协议、测试数据集、采样量或方差信息。这不是一份评测报告,而是一份营销向的成果展示。
方法论质疑
每个 Benchmark 都有局限,这一条也不例外:
- 测试条件不透明:batch size、序列长度、并发用户数、显存占用率等关键参数均未披露。这些变量对吞吐测试结果影响极大。
- 对比基准模糊:声称"超越 Hopper",但 Hopper 侧是哪种配置?单卡?8-GPU NVL36?还是同等规模的集群?均无说明。不同配置的性价比完全不同。
- 无统计显著性说明
● 未登录访客SMARTFLOW PRO
继续阅读深度解读 + 编辑加注
下方还有 3-5 段深度分析 + Vincent 编辑加注 + 可点击信源,仅 Pro 会员可见
加入机智流 PRO →¥99 / 季 · 每周 1 篇深度研报 · 飞书+微信群双通道
已是 Pro 但仍被提示?联系反馈
参考来源
- Perplexity 原文 · 2026-05-12
- NVIDIA GB200 NVL72 规格 · 2026-01-01
本解读由 AI 自动生成 · 模板:评测解读 · 仅供参考,请以原文为准。