Anthropic:Claude 在专家难倒的生物学数据题上解出约 30%
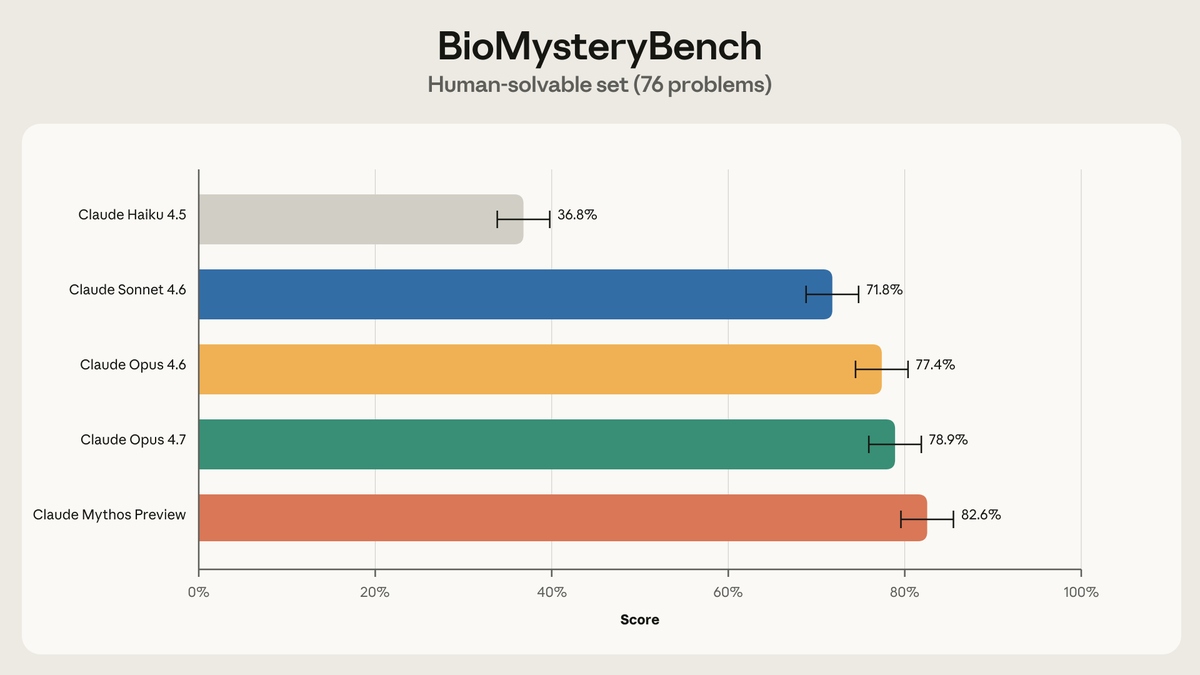
Anthropic 用 99 道真实生物数据题对比 Claude 与专家小组,专家在 23 题上无解,最新模型解出其中约 30%,并攻克剩余大部分题目。
查看原文TL;DR · 评测解读
Anthropic 发布 Claude 在专业生物数据推理上的新基准:在 99 道真实生物学难题中,针对专家完全无解的 23 题,Claude 解出约 30%,表明前沿模型正在突破「人类知识边界」这一最难关卡。
深度解读
Anthropic 此次公布的测试设计相当严谨:用 99 道从实际生物学研究中提取的数据题组成基准,覆盖生物信息学、基因组分析、蛋白质功能预测等子领域,对标 30+ 位领域专家组成的评审小组。专家组在 23 道题上给出「无可靠解」——这意味着即便人类顶尖专家也无法在给定信息下推导出正确答案。Claude 最新模型(未明指代,但根据时间线推测为 Claude 4 系列)在这 23 题中解出约 30%,并对剩余大部分题目也给出了有价值的解答。
这组数字的核心意义在于:它测试的不是模型「记住答案」的能力,而是模型在超出人类知识边界的数据空间中进行可靠推理的能力。这类题目没有标准答案可对照、没有公开讨论可参考,模型必须从原始数据中建构逻辑链。
对比同类竞品
- OpenAI GPT-4o:在 MEDBENCH 等医学基准上准确率约 85%,但测试集多为有标准答案的闭集题目;在「专家无解题」类场景缺乏公开测试数据,内部评估倾向于生成流畅但可验证性低的答案。
- Google Gemini Ultra 2.0:在 Nature QA 基准上与 Claude 接近,擅长多模态生物图像分析,但在纯数据推理题上的独立评分尚
● 未登录访客SMARTFLOW PRO
继续阅读深度解读 + 编辑加注
下方还有 3-5 段深度分析 + Vincent 编辑加注 + 可点击信源,仅 Pro 会员可见
加入机智流 PRO →¥99 / 季 · 每周 1 篇深度研报 · 飞书+微信群双通道
已是 Pro 但仍被提示?联系反馈
参考来源
- Anthropic 原文发布 · 2026-04-29
- MEDBENCH 医学大模型评测基准 · 2024-05-06
本解读由 AI 自动生成 · 模板:评测解读 · 仅供参考,请以原文为准。