vLLM:发布 Triton 统一注意力后端,800 行代码跨 NVIDIA/AMD/Intel 三平台
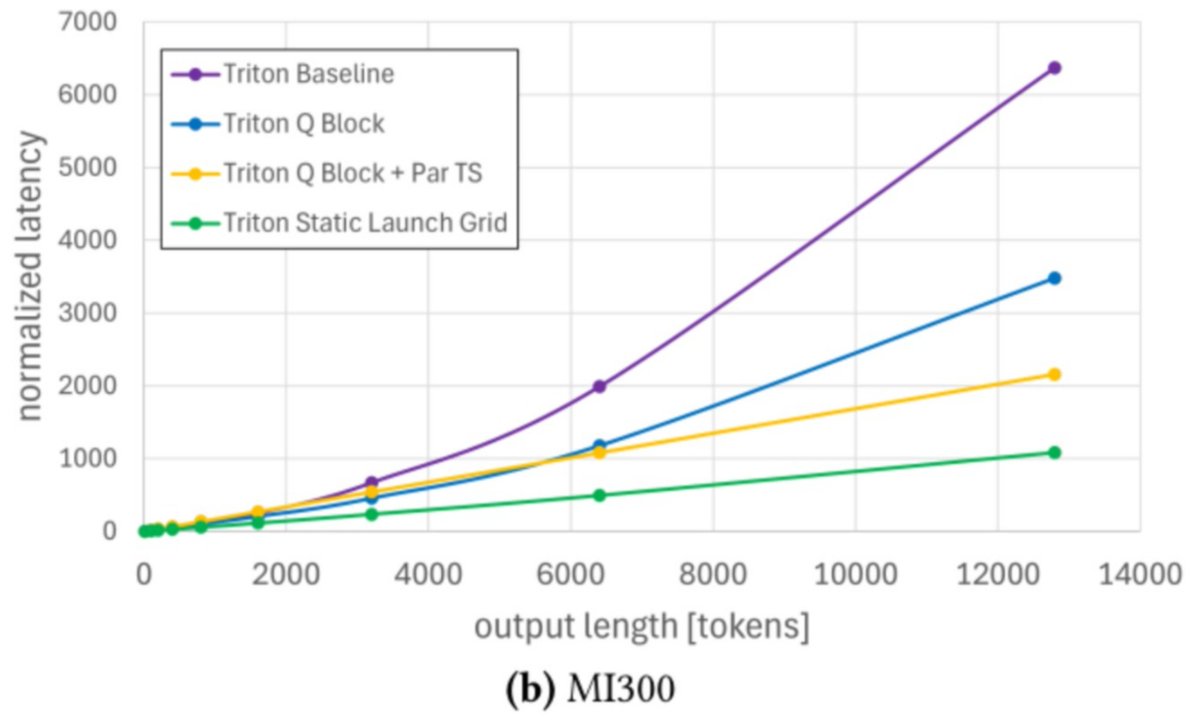
vLLM 推出基于 Triton 的统一注意力后端,仅约 800 行代码即可在 H100 上匹配 SOTA 性能,在 MI300 上比此前实现快约 5.8 倍,解决跨 GPU 平台维护难题。
查看原文本解读由 AI 自动生成 · 模板:事件解读 · 仅供参考,请以原文为准。
vLLM 推出基于 Triton 的统一注意力后端,仅约 800 行代码即可在 H100 上匹配 SOTA 性能,在 MI300 上比此前实现快约 5.8 倍,解决跨 GPU 平台维护难题。
查看原文